
李川皓 投稿
量子位 | 公众号 QbitAI
一个5月份完成教师的大模子,无法对《黑传奇·悟空》游戏内容相关问题给出准确回话。
这是大模子的老过错了。
因为《黑传奇》8月才上市,教师数据里莫得它的相关知识。

人所共知,大模子的教师和微调会耗尽多数经营资源和时分,这意味着平凡更新大模子的参数是不切试验的。
关联词,现实天下中的信息是及时产生的且不断变化的。这使得大模子在完成教师后,关于后续新产生的信息感到生疏,是以无法提供准确可靠的响应。
为此,上海东说念主工智能实验室、北京理工大学、浙江大学、香港大学兼并提议即插即用的SearchLVLMs框架,不错无缝整合大肆的多模态大模子。
该框架在推理阶段对大模子进行互联网检索增强,使得大模子无需微调即可对及时信息进行准确的响应。

扣问团队提议首个支持多模态大模子对及时信息进行响应的开源检索增强框架SearchLVLMs。
该框架主要包括查询生成、搜索引擎调用、分层过滤三个部分。
以视觉问答为例,该框架会基于问题和图片生成查询枢纽词,并调用搜索引擎查找相关信息,再由粗到细地对检索杀青进行过滤,得到对回话该问题有匡助的信息。
这些信息会以prompt的体式在推理阶段提供给模子,以支持回话。
同期,团队提议一个数据生成框架UDK-VQA,它不错自动生成依赖及时信息进行回话的视觉问答数据。
基于此框架,数据集不错完成动态更新,以保证测试数据的时效性。
当今已有UDK-VQA-240401-30、UDK-VQA-240816-20两个版块的数据集,波及到的时分跨度差别是2024年4月1日-2024年4月31日和2024年8月16日-2024年9月5日。
扣问者在跳跃15个开源、闭源模子上进行了实验,包括GPT-4o、Gemini 1.5 Pro、InternVL-1.5、LLaVA-1.6等。
在UDK-VQA数据集上的回话准确率,则配备了SearchLVLMs的SOTA LVLMs跳跃了自带互联网检索增强的GPT-4o模子35%。

开源框架SearchLVLMs
SearchLVLMs框架主要由三部分构成:
查询生成搜索引擎调用分层过滤在查询生成阶段,需要对问题和图像进行充分地勾搭,以回荡为适用于搜索引擎的文本查询。
关于问题而言,胜利使用手工联想的prompt调用LLM得到问题查询词。
关于图像而言,调用必应视觉搜索得到包含该图像或与该图像相关的网页,索求这些网页的题目/快照的最长巨匠子串手脚图像查询词。
在搜索引擎调用阶段,用户不错凭据问题类型自主聘用调用的搜索引擎类别。
比如:关于及时性较强的新闻相关问题,不错聘用调用必应新闻搜索;关于学问性问题,不错聘用调用必应通用搜索。
调用搜索引擎后会得到多个网页的题目、纲目和联贯。
在分层过滤阶段,早先调用网页过滤器对得到的网页进行初筛,基于网页的题目和纲目对这些网页进行重排。
关于排序靠前的网页,使用爬虫取得网页的文本内容,每三句切分红一个片断,使用内容过滤器对这些片断进行重排。
关于排序靠前的片断,基于CLIP特征对它们进行聚类,聘用离每个聚类中心的最近的片断,以幸免内容重迭片断对大模子估量带来的误导。
被聘用的片断被胜利拼接在一说念,用于指示大模子。
其中,网页过滤器和内容过滤器是两个寂然教师的LLaVA-1.5模子,作用是为网页/片断进行打分——网页/片断关于回话该问题的匡助进度。
为了教师这两个过滤器,也为了测试大模子对及时信息的响应能力,扣问团队进一步提议了一个数据生成框架——UDK-VQA,如下图所示。
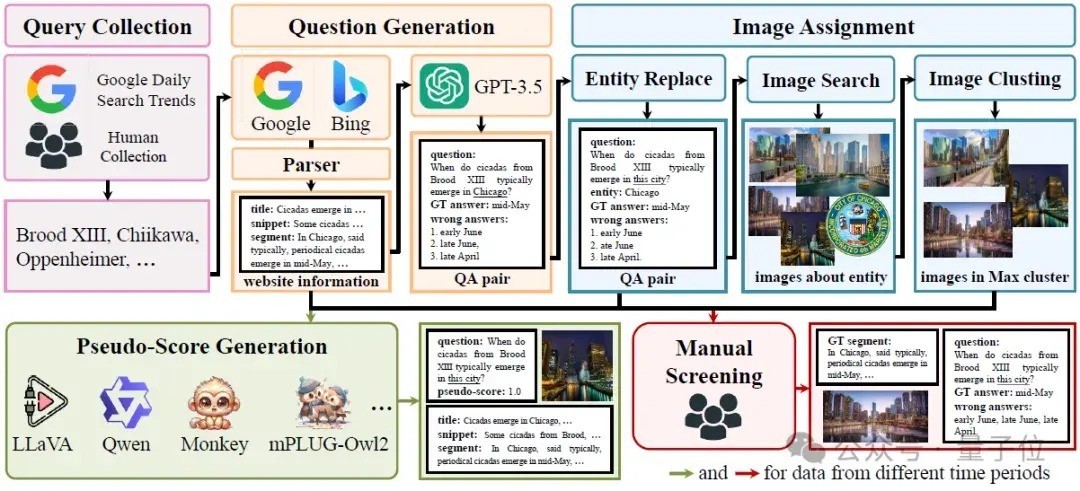
五个要道完成数据生成
UDK-VQA数据生成主要遵命五个要道:
差别是查询征集、问题生成、图像分拨、伪标注生成、东说念主为考证。
第一步,查询征集。
查询征集主要包括两方面,一方面是从谷歌逐日搜索趋势上爬取热点搜索词,另一方面是东说念主为征集一些热点搜索词来对前者进行补充。
第二步,问题生成。
扣问东说念主员早先凭据征集到的搜索词调用搜索引擎得到相关的新闻,将新闻内容进行切分,得到多个内容片断。
然后条目GPT凭据内容片断自问自答,得到<问题,谜底>的鸠合。
在第三步图像分拨阶段,团队会索求出问题中的实体,使用图片搜索引擎得到实体的图片,并将问题中的实体单词替换为其上分位词,与图片一说念构成视觉问答样本。
第四步,伪标注生成。
为了教师网页过滤器和内容过滤器,需要对网页/片断进行打分。
关于一个视觉问答样本和一个网页/片断,扣问者基于两个原则进行打分:
① 若是该样本是基于该网页/片断生成的,分数为1.0。
② 若是该样本不是基于该网页/片断生成的,使用5个开源模子在该网页/片断下尝试回话该样本,凭据模子回话的正确率进行打分。
基于这么的伪标注措施,扣问东说念主员构造了~80w样本用于教师。
终末一步,东说念主为考证。
构造测试集时,扣问者对第3步得到的视觉问答样本进行了东说念主为筛选,确保测试样本的正确性。
为了幸免教师数据和测试数据需要参考相同的及时信息,在构造教师集和测试集时,扣问历程中使用不同技艺区间的谷歌逐日搜索趋势来爬取热点搜索词。
下图中(a)、(b)、(c)差别展示了教师样本、测试样本和测试样本的散播。

基于数据生成框架UDK-VQA,很容易不错构造出需要及时信息进行回话的视觉问答样本。
扣问团队声明会不断更新测试集,保证测试样本的时效性。
当今,扣问东说念主员仍是构造了两个版块的测试集,差别波及到2024年5月份和2024年9月份的信息。
实验杀青与论断SearchLVLMs框架团队在UDK-VQA上测试了15个现存的LVLMs,主要实验杀青如下表所示。
其中,Raw示意模子的原始版块(莫得检索增强功能)、Long-Context (LC)示意将搜索引擎复返的网页爬取内容后,胜利拼接起来指示模子,IAG示意使用了模子内嵌的互联网检索增强能力。
Gen.、Cham.和CLIP→FID (C→F)差别示意[1]、[2]和[3]中的措施。

从实验杀青中不错有以下发现:
1、接受长潦倒文输入不错一定进度上幸免对搜索引擎的复返内容进行二次筛选。
Gemini Pro 1.5 (LC)的性能高于内嵌互联网检索增强的GPT-4V和GPT-4o,然而长潦倒文会引入迥殊的经营耗尽,并引入一些无须要的信息对模子变成误导。
经过SearchLVLMs的分层过滤模子进行二次筛选还有,不错进一步提高模子性能。
2、具备检索增强能力的闭源商用模子在性能上权贵高于不具备检索增强能力的开源模子。
GPT-4V和GPT-4o由于内嵌互联网检索增强模块,在准确率上大幅最初开源模子,如LLaVA-1.6和InternVL-1.5,差距约为20%~30%。
3、SearchLVLMs框架不错整合大肆的多模态大模子,并大幅度提高它们关于依赖及时信息的问题的回话能力。
不管是在闭源商用模子Gemini 1.5 Pro、GPT-4o、GPT-4V,如故开源SOTA模子LLaVA-1.6和InternVL-1.5上,SearchLVLMs均能带来跳跃50%的性能提高。
4、SearchLVLMs带来的性能提高,远高于已有措施。
扣问对比了检索增强措施Gen.、C→F和调用搜索引擎来支持回话的框架Cham.,SearchLVLMs在搪塞及时信息检索任务时,推崇出昭彰的优胜性。
5、使用SearchLVLMs整合开源模子,性能不错大幅跳跃内嵌互联网检索增强能力的闭源商用模子。
InternVL-1.5+SearchLVLMs的准确率为92.9%,远高于GPT-4o(IAG)的57.8%。
这一发现标明,开源模子具有普遍的后劲,SearchLVLMs在性能、可定制性和透明度上具有权贵的上风。
参考文件[1] Yu et al. Generate rather than retrieve: Large language models are strong context generators. arXiv 2023.
[2] Lu et al. Chameleon: Plug-and-play compositional reasoning with large language models. NeurIPS 2023.[3] Chen et al. Can pre-trained vision and language models answer visual information-seeking questions? EMNLP 2023.著作联贯: https://arxiv.org/abs/2405.14554
技俩主页:https://nevermorelch.github.io/SearchLVLMs.github.io/
— 完 —
量子位 QbitAI · 头条号签
眷注咱们欧洲杯体育,第一时分获知前沿科技动态约